How Qri Defines a Dataset
In Qri, 'Dataset' means more than just the data.
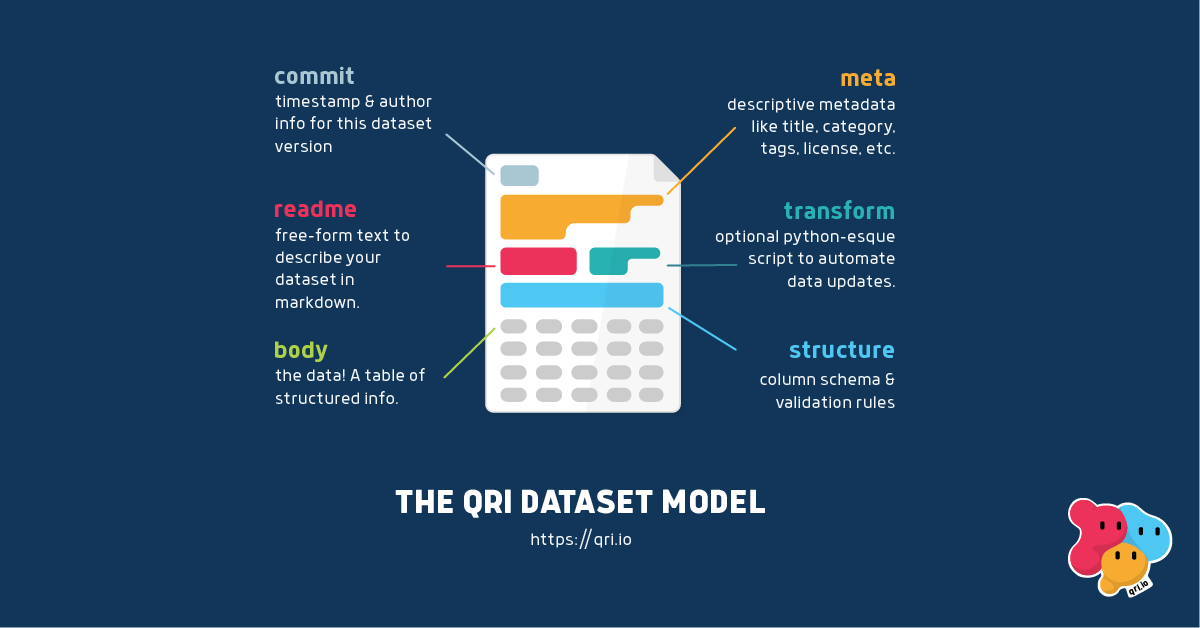
The Dataset Model
Qri defines a dataset as a set of components, each with its own format and requirements. When we say "dataset", we mean all of these components together, under a unique qri username/datasetname combination. The data itself lives in the body component of the dataset. A Qri dataset contains everything you wish you had when you download a CSV of data from the internet.
Our data model brings together several best practices used in managing data. Most importantly, metadata is an integral part of the dataset. It doesn't live somewhere else, it's a first-class citizen and goes everywhere the data goes. Beyond that, we've added readme, a common file used in the coding world used for documentation, transform, for storing code used to update the data, and structure for storing things like column descriptions, stats, and information about how the body is encoded.
Finally, the commit component stores information relevant to a given version of the dataset. What changed, and why?
Datasets are Immutable and Versioned
A change, large or small, to any individual component in a Qri dataset constitutes a new version of the dataset. Changing the dataset's description text in meta is just as much a change as deleting 90% of the rows in body, and will yield a new version once the changes are committed.
Calling a dataset by its unique username/datasetname is really saying "give me the latest version of this dataset's components"
Read more about versioning in Qri
Components
body
The body component is a collection of structured data. The other components of a dataset are information that complements the body (metadata, structure information, column types and descriptions, etc.), but body is the data itself.
body is commonly a single CSV of data, but can include other data formats such as JSON, XLSX, and CBOR.
Body is a required component. A Qri Dataset cannot exist without a body.
readme
The readme component is free-form text used to describe a dataset. Often structured metadata fields aren't a sufficient mechanism for explaining the nuances of a dataset. readme allows for more human-friendly language to explain the dataset to other Qri users. Markdown is supported for adding hyperlinks, images, headers, and other rich text.
A readme component is not required, but adding a readme is a best practice for creating healthy datasets in Qri.
Sample Qri readme:
# My Nifty DatasetThis dataset is a cleaned up version of some canonical dataset published at [this open data portal](https://data.somecity.gov)## CleanupTo cleanup the original data, I used R studio to concatenate `column_a` and `column_b` into `column_c`## Time Zone Warning`timestamp_column` has no timezone specified, so some programs may import it as UTC. Be sure to offset for local time on import.## Contact meFind me on twitter as @some_data_user if you have any questions or want to collaborate!
meta
The meta component contains machine-readable metadata that qualifies and distinguishes a dataset.
Well-defined meta should aid in making datasets discoverable by describing a dataset in generalizable taxonomies that can aggregate across other datasets.
Because datasets are intended to interoperate with many other data storage and cataloging systems, meta fields and conventions are derived from existing metadata formats whenever possible. However, meta is extensible and users may define any key/value pairs as needed.
Sample Qri meta:
{"description": "( 1 ) United Nations Population Division. World Population Prospects: 2017 Revision. ( 2 ) Census reports and other statistical publications from national\nstatistical offices, ( 3 ) Eurostat: Demographic Statistics, ( 4 ) United Nations Statistical Division. Population and Vital Statistics Reprot ( various years ),\n( 5 ) U.S. Census Bureau: International Database, and ( 6 ) Secretariat of the Pacific Community: Statistics and Demography Programme.\n","downloadURL": "http://api.worldbank.org/v2/en/indicator/SP.POP.TOTL?downloadformat=csv","homeURL": "https://data.worldbank.org/indicator/sp.pop.totl","keywords": ["united nations","population","world bank","census"],"license": {"type": "CC-BY-4.0","url": "https://creativecommons.org/licenses/by/4.0/"},"qri": "md:0","theme": ["population"],"title": "World Bank Population"}
transform
The transform component binds code to a dataset. Common uses for the transform component are:
- Fetching html from the web & coercing it into structured data (scraping)
- Automating data cleanup tasks
- Running calculations on dataset values to produce new ones
- Combining 2 or more datasets
transform scripts allow for an audit trail & easy repeatability. Qri executes transforms in a sandbox, with no access to the local filesystem, and controlled internet access.
Qri transforms are written in Starlark, a programming language similar in syntax to Python3.
Sample Qri transform:
# load starlark dependenciesload("http.star", "http")load("dataframe.star", "dataframe")---# fetch a dataset of popular baby names from the NYC open data portalcsvDownloadUrl = "https://data.cityofnewyork.us/api/views/25th-nujf/rows.csv?accessType=DOWNLOAD"res = http.get(csvDownloadUrl).body()---# get the latest version of the dataset to use as a working datasetds = dataset.latest()# set the body of the working dataset to be the fetched datads.body = dataframe.parse_csv(res)# commit a new version of this datasetdataset.commit(ds)
structure
The structure component defines the characteristics of a dataset document necessary for a machine to interpret the dataset body.
Structure includes things like the encoding data format (For example, CSV), length of the dataset body in bytes, etc, and is stored in a rigid form intended for machine use. A well defined structure & accompanying software should allow the end user to spend more time focusing on the data itself.
Qri will infer a dataset's structure automatically if one is not provided with a commit.
Sample qri structure:
{"checksum": "/ipfs/QmfCSGGkHNXcDpSuoHyFnEjUsJheq3NoHqkdmxhScXiGi7","depth": 2,"entries": 37537,"format": "csv","formatConfig": {"headerRow": true,"lazyQuotes": true},"length": 1517392,"path": "/ipfs/QmYSdJygHwoQffvMyFKN8QdXTvkSzTwhCDhJ1sE9U39LSb","qri": "st:0","schema": {"items": {"items": [{"title": "year_of_birth","type": "integer"},{"title": "gender","type": "string"},{"title": "ethnicity","type": "string"},{"title": "childs_first_name","type": "string"},{"title": "count","type": "integer"},{"title": "rank","type": "integer"}],"type": "array"},"type": "array"}}
commit
The commit component contains details about the creation of a new version of a Qri dataset. It includes a title (short-form description) and message (long-form description) of the changes, usually provided by the user. It also contains the timestamp, author identifier, and a cryptographic signature linking the author to the commit.
Commit is directly analogous to the concept of a Commit Message in the git version control system. A full commit defines the administrative metadata of a dataset version, answering "who made this version of the dataset, when, and why".
Sample Qri commit:
{"author": {"id": "QmNj6CEjSKrTzNR6k8iUpZVurboisAVNebG3mJ8JoWFDba"},"message": "transform:\n\tupdated steps.0.script","path": "/ipfs/QmZ5Kq7XVmeBubgDAv3e7rchexvwtqywCyTquqcAR5vVHJ","qri": "cm:0","signature": "pRJ42EsUOXG08DHNUpD6UPVgdICwV1fo7C7ZfwRCo8iBP8PW10HDgr7juksvU9uxevlLFvaKodzitFkD27Oej55l2YGBsluB8/P40HAIluLyaWO95kskmLTYOmAeB3w6Gh3UhyXjrZ04Sgp8kvXii5OzlTnZkomgQ9nxXFG2Zud8Zm/RHN0SMV8+lwKMi3Y+cZsdkH76JtBEMQDaiVp34oevmbY57wyFqJROFTD/LVErzAs0K7bsRmxYEtNTPlEXpWrzDHaPU0X1EVqMfBvsfKnMcWIgU972KHWZDPVyfAwrt8Vv6hy//ZGJYVu3fiKsik/Jy6mHAaC4y6c5aibD3A==","timestamp": "2021-08-16T15:02:18.627086Z","title": "transform updated steps.0.script","runID": "3fdeb339-0d51-4660-8d0b-0ce17e067ef4"}